|
英伟达特供版AI芯片H20更新!
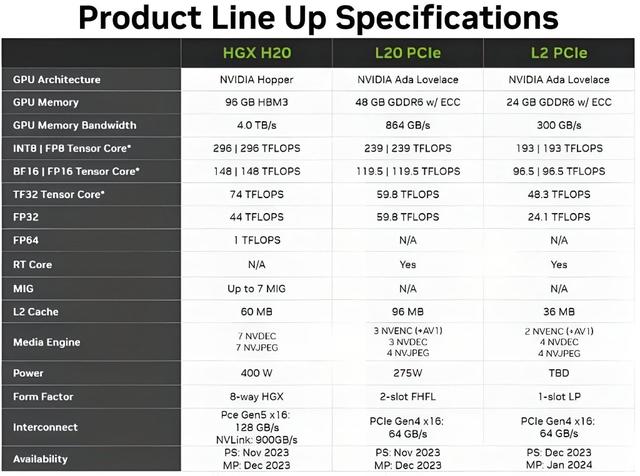
事件:Nvidia英伟达对华“特供版”AI芯片H20的终端产品已可接受预订。根据草根调研,单卡售价根据性能外推预期在1.3-1.4万美金,国内有两家大厂已向英伟达下订单采购数万片H20,乐观Q2出货。全年H20出货量可能会在大几十万片,之前的市场预期应该是30万片左右。同时,英伟达另一中国特供版芯片L20 PCIE目前也在测试中,即将启动采购。
事件:英伟达对华“特供版”AI芯片H20的终端产品已可接受预订。根据草根调研,单卡售价根据性能外推预期在1.3-1.4万美金,国内有两家大厂已向英伟达下订单采购数万片H20,乐观Q2出货。全年H20出货量可能会在大几十万片,之前的市场预期应该是30万片左右。同时,英伟达另一中国特供版芯片L20 PCIE目前也在测试中,即将启动采购。
国产算力趋势非常明确、持续关注国产算力链我们认为,两家大厂关于H20的大单并不会冲击国产算力演绎逻辑。国产算力的趋势是明确且不可逆的。一方面,我国对芯片国产化的支持力度强而持续。国产芯片持续自主迭代,在实践中性能得到大幅提升。另一方面,近年来美国持续升级对华制裁,今年1月以来更是多方面收紧我国获取先进计算能力的途径。

算力国产化是必由之路。国产芯片占比持续提升
测算了 23、24年我国AI芯片市场各家占比情况。国产芯片占比可能从去年25%左右提升至40%到45%。
此次H20订单较超预期、建议关注中国NV链去年年底至今,国内外对H20在华出售的预期较为悲观,此次两家大厂的订单较超预期,建议关注浪潮信息、紫光股份等相关标的建议持续关注国产算力
H20:是高缓存、高带宽,但是算力性能差,这主要是M国禁令的要求和限制。H20卡算力性能差,大约是HW昇腾910算力的一半,缓存与带宽是比910B高,带宽是910B两倍。NV有NVlink架构。英伟达的卡是通过多卡使用、多卡堆叠模式,与国内HW的高算力的卡抗衡。国内910B的性能与A100单卡很接近,1)国内的卡弊端是互联带宽弱,卡间、AI服务器间弱;2)软件生态不够成熟。英伟达的卡是在这个软肋的基础上推出的,在互联带宽与CUDA生态上做的。
Q&A
Q:H20是H800做训练的6-7成。原来H的时候,算力使用效率是3-4成,新的H20加大带宽,组成集群的大模型训练效率可能比H800更好吗?
A:国内软件训练框架比较弱,国内是GPT1.0\2.0架构为主,H800算力性能很高,但还是在几百万的训练参数方面没有办法使用起来,H800使用效率很低。但是H20方面,更容易取得训练参数不是很高的方面,很适合多卡堆叠与多个AI服务器的使用。
Q:改良版芯片是更容易大模型训练的吗?
A:国内大模型训练方面,不能单独看硬件。一是卡,二是框架。GPT4.0是基本囊括国内所有知识,但国内3.0、4.0都没办法用,正规渠道都是1.0/2.0,训练参数、性能都局限了。即使H100有卡也训练不出来,因为底层软件有局限。英伟达推出H20的卡,是可以通过国内客户多买卡实现与A100、H800同样效率。NV可以多买卡,又满足美国禁令,也不会让基于GPT2.0训练模型框架训练处更高的模型,这个模式也是一举多得的。NV不会完全切断NV与国内的来往,硬件可以给,但是软件层面切断,国内没办法用千亿级训练模型的框架。 NV的IB交换机,光模块的400G\800G不是必须的。因为H100 AI服务器,可以用400G光模块,也可以800G(8张卡是4个800G光模块)。因为AI服务器数量多了,光模块数量也会多的。组网方面,是NV用ib交换机,正常组网还是以太网交换机。
Q:H20产品的HBM3是一个板用了3个,就是算力是A100的30%,HBM用量一样?
A:单卡的HBM量与H800相近,H20的cowos的制程与800相比更简单。卡的算力高低,在于晶元制程,nm越低,集成度越高,算力越强。H20的算力来看,设计工艺是一般,还不如910B的算力设计工艺好。代工厂而言,可以用一些比较差的制造工艺来复用,成本下降了。唯一是HBM的好了,价值量3倍。
Q:H20的NVLINK是900GB/S,H800只是400,可以达到吗?
A:NVLINK对NV不是高端的,很成熟了,H系列都可以支撑。网络带宽支撑这么大,可以买更多的卡达到,nvlink的传输速度可以领先的。昇腾达不到的,现在是400G,8卡一连就是200了。
Q:训练框架是指?
A:训练模型都是用语言框架支撑,软件框架。软件更新换代,或者技术迭代,国内训练语言框架方面,软件版本比较低,为1.0、2.0,海外升级到GPT 4.0版本。API端口不给国内账户申请试用,所以体会不到4.0里面软件功能。美国封锁A100\H100是不愿意分享制造工艺。
Q:为什么H20卡不需要covos封装?
A:看到有HBM,但是cowos是4或3nm以上,是高端封装,所以A100\A800\H20,制造工艺不像H100那么高,所以封装架构不需要cowos,成本下降。明年H100北美需求旺盛,所以不会为了中国的量,占用封装产能。
Q:对算力租赁影响?
A:从前大部分是A\H800,但是现在对于禁令以后,算力租赁停滞了。现在NV推出H20以后,可以组建算力中心、算力租赁中心。可以通过NVLINK、IB网络架构,使用多张H20,多个基于H20的AI服务器,搭建数据中心。大部分算力公司是基于cuda架构的,H20的出现会帮助算力租赁中心缓解数据中心搭建的缺卡情况。
Q:是不是可以理解为缓解算力的短缺,限制算力的涨价,对算力租赁公司偏利空?
A:算力公司来讲,是利空的状态。算力租赁行业对卡的依赖性很强,没有生存的价值。
Q:H20可以保留NVLINK,此前带宽要求不影响了吗?
A:限制A\H100时候,有限制网络互联带宽。但是现在11月份对H800禁令来看,取消带宽限制。这是美国政府的问题,如何既不给高端卡,但是不切断业务来往,买更多的卡,达到A\H100的性能。NV会对NVLINK卡间互联做文章,堆叠卡提升性能,是一个好的商业模式。
Q:H20组成集群的性能与HW的比较?
A:服务器卡间瓶颈,服务器间瓶颈。卡间互联910B的互联带宽是H20的一半,卡间互联性能下降一半。服务器间互联,英伟达有一分半IB交换机,没有替代解决方案。国内是400、800G集群交换机,算力损耗比较大。
Q:昇腾卡的性能对标A100,软件方面差距在哪里?
A:1)软件方面,商用的软件方面,基本的高端软件都是海外的软件公司。国内公司做兼容性适配是很困难的,NV的出卡之前会做相应性能兼容性测试与调优,所以NV在销售平台上使用方面是最好的。
2)国内卡的客户在互联网公司,他们不会用商业软件,是开源软件做开发,因为每个互联网公司商用方式不同,会做一些开发。他们用互联网的自研平台,迁移适配到国内的卡方面,适配成本迁移成本比较低。大家对互联网行业很关注,国内芯片行业对其也很关注,因为切入NV中,互联网是最容易切入的,没有商业软件的影响,都是自研。软件开发周期比硬件长得多。
Q:17号禁令下单之后,会有H20订单的转换吗?还是再次重新下单呢?
A:禁令以后得订单取消掉了,NV的取消。所以H20的订单是重新来的,不能同等替代。
Q:阉割版上市有用吗?客户端需要4多久业务适配?
A:英伟达的卡在于互联网公司,适配到小批量-大批量,需要半年时间,从引入测试到小批量是半年。卡的阶段是英伟达的设计完成,自身做检测,但没有下方代工厂商,交付给互联网引入测试,下方给服务器代工厂小批量生产调试,再做小批量供应,与互联网同步,半年采购。
Q:大家从训练模型的角度,到底是看INT8还是看FP16甚至是FP32,感觉说法很多,我们评判国内外的卡主要是看哪个指标的算力呢?
Q:主要是FP32与FP64,FP16是国内由于设计工艺原因,没办法达到,真正看浮点运算,还是FP32与FP64。英伟达基本不会做FP16浮点运算参数。国内模型框架,FP16还是可以用的,但还是一旦训练参数激增,就是FP32与FP64。
Q:相对H100等先进芯片,NV变通方案会对成本上升多少呢?
A:运营成本上升会与卡的采购量上升成正比的。以一个通俗例子来看,H100的卡的运营成本,与H800的成本不同,空间、功耗、人员费用方面,卡的费用都是很高的。H20比H100功耗有一些下降,但是比A100提升不少,通过H20来看,未来大批量使用的成本提升A100的3-4倍,比H100低一些。
Q:H20使用液冷方案吗?
A:H20是风冷,液冷还是H100,750w功耗。H20加了2-3张卡,功耗是A100的3-4倍。
Q:H20组网会比原先的H800组网增加功耗及散热需求吗?
A:H20的散热会低于H800,因为算力、功耗低,散热会低的。
Q:现在英伟达有了合规产品,但是由于单卡算力降下,是不是意味着同样算力集群需要更多的服务器?
A:会的,H20留下很多带宽的原因,让国内的用户实现一些堆叠。
Q:假设有足够买卡资源和不考虑能耗,基于H20算力集群算力能否达到基于H100算力集群算力?
A:可以的。
免责声明:文章来源网络及其他媒体平台,转载目的在于传递更多信息,仅代表作者个人观点,不确保文章的准确性,如有侵犯版权请告知,我们将在24小时内删除!
H20 平台NVQD02接头
- 不锈钢
- EPDM密封
- 单手连接或断开
- Cv值高,高流量低压降
- 连接力小,轻松连接
- 色带清晰,阴接头有色套筒,阳接头有色密封
- 100% 氦气检测
- 规格: NVQD02和NVBQD02
H20 平台NVBQD02盲插接头
- 不锈钢
- EPDM密封
- 单手连接或断开
- Cv值高,高流量低压降
- 连接力小,轻松连接
- 色带清晰,阴接头有色套筒,阳接头有色密封
- 100% 氦气检测
- 规格: NVQD02和NVBQD02

关于我们
北京汉深流体技术有限公司是丹佛斯中国数据中心签约代理商。产品包括FD83全流量自锁球阀接头,UQD系列液冷快速接头、EHW194 EPDM液冷软管、电磁阀、压力和温度传感器及Manifold的生产和集成服务。在国家数字经济、东数西算、双碳、新基建战略的交汇点,公司聚焦组建高素质、经验丰富的液冷工程师团队,为客户提供卓越的工程设计和强大的客户服务。
公司产品涵盖:丹佛斯液冷流体连接器、EPDM软管、电磁阀、压力和温度传感器及Manifold。
未来公司发展规划:数据中心液冷基础设施解决方案厂家,具备冷量分配单元(CDU)、二次侧管路(SFN)和Manifold的专业研发设计制造能力。
- 针对机架式服务器中Manifold/节点、CDU/主回路等应用场景,提供不同口径及锁紧方式的手动和全自动快速连接器。
- 针对高可用和高密度要求的刀片式机架,可提供带浮动、自动校正不对中误差的盲插连接器。以实现狭小空间的精准对接。
- 基于OCP标准全新打造的UQD/UQDB通用快速连接器也将首次亮相, 支持全球范围内的大批量交付。
|




