|
 |
|
||||||
|
|
|
|
大模型训练场景,模型规模大且在持续增长、数据量大且多样化、计算密集且耗时长、计算资源消耗巨大,对计算能力、吞吐量和精度要求极高,训练过程追求快速收敛和时效性,因此,对AI服务器的核心诉求是:更大的计算规模、更大的缓存容量、更大的通信带宽。
大模型推理场景,单次推理数据量不大,但涉及的数据离散性较大,对算力和缓存有平衡性要求,尤其是PD分离部署架构下,不同阶段的算力和缓存配比要求不同,推理过程追求快速响应和用户体验,且要求更低的推理成本,因此,对AI服务器的核心诉求是:较大的单域计算规模、灵活的缓存配比、更低的通信延时。
随着大模型的竞赛进入第一节的后半场,即大模型推理阶段,各种推理大模型工具、AI助手、图文等多模态内容理解与生成、视频生成等等,层出不穷。这一时期,AI服务器的设计更应该关注大模型推理的诉求:单域算力规模、低延时通信、灵活算力和缓存配比、更高的性价比。
然而这些因素之间既有相互依赖、又存在相互制约。算力和缓存大小可以在GPU芯片调整,但是大模型推理中,不同应用场景、不同计算阶段的算力和缓存密集度要求是不同的。
使用万相wan模型做视频生成的场景,对算力密度要求更高,对缓存容量要求适中;
采用PD分离部署的千问Qwen混合专家模型,Prefill阶段是算力密集型场景,对缓存容量要求不高,但在Decode场景则是对缓存容量和带宽要求更高。
KVcache的提出也是为了减少计算,采用缓存空间换取计算时间的原理,但随着KVcache数量的累积,对于KVcache存取的优化,后文会在通用计算超节点的设计中展开介绍。
因此GPU芯片的异构化,在不同场景、不同节点采用异构的GPU芯片,也是AI服务器的考虑要素,但与此同时也会增加芯片间通信的带宽和低延时要求。在模型规模和算力诉求持续增长,单一的计算芯片算力有限、单一的缓存芯片容量有限的条件下,大模型训练/推理服务器的设计命题核心就指向了芯片互连,即:超节点服务器互连设计。
先来回顾一下磐久AI Infra2.0 AL128超节点服务器硬件系统:
整柜采取定制双宽机柜方式:整柜支持128~144颗GPU芯片,支持高达350kw供电能力和500kw散热能力,支持单颗GPU芯片2kw的液冷散热能力,采用BusBar柜内集中供电。
灵活的模块化、多维解耦系统架构:CPU节点与GPU节点解耦、GPU节点与ALink SW节点解耦、算力节点与供电节点解耦,不仅可以兼容行业主流CPU、GPU、ALink SW芯片,还可以灵活支持主力芯片独立演进、CPU与GPU数量的灵活配比。
GPU节点与ALink SW节点采用正交互连架构:实现高速链路极致低损耗,还减少了繁杂的cable布线和耦合,提高了系统的可靠性和可运维性,将FRU的颗粒度从柜级缩小到节点级,FRU更换时长从小时级缩减到分钟级。
系统互连采用单级互连架构,采用非以太ALink协议:支持UALink国际开放标准协议,也可支持行业主流GPU芯片的原生内存语义互连协议,如:NVLink、xLink、UB、xCN等。
从机柜前视图来看,超节点的左侧为GPU节点与ALink SW节点正交互连区域,分为上下两组AL64卡ScaleUp域,后续会支持一组AL128卡ScaleUp域,正交架构促使高速链路极致低损耗,实现GPU和ALink SW的112G/224G Serdes,系统可靠性更高。
超节点的右侧部署CPU节点和Powershelf供电节点,CPU节点与GPU节点左右分离布局,实现了CPU节点与GPU节点的灵活搭配能力,可以灵活支持单OS下8/16/32张GPU卡的灵活配置组合,同时CPU节点与GPU节点可以实现跨平台、跨代次的灵活搭配,为支持GPU芯片异构化提供了灵活的能力。
接下来看磐久超节点服务器互连架构是如何实现的。
当下推理场景,LLM模型参数规模大,Qwen3-max超1万亿参数,单推理任务8~32颗GPU芯片已经可以进行部署,但考虑到大EP的发展趋势和长会话场景的KV Cache存储需求,32~128颗GPU芯片能提供更优秀的用户体验。
Sora2和Wan2.2这类视频生成模型采用DiT扩散模型,参数规模不大,但算力要求更高,32颗GPU芯片可以获得较高的并行化加速甜点。再综合考虑云计算对资源调度、灵活性的诉求,64~128颗AI芯片互连的超节点,已经可以在未来3年内满足绝大多数推理应用的部署要求。
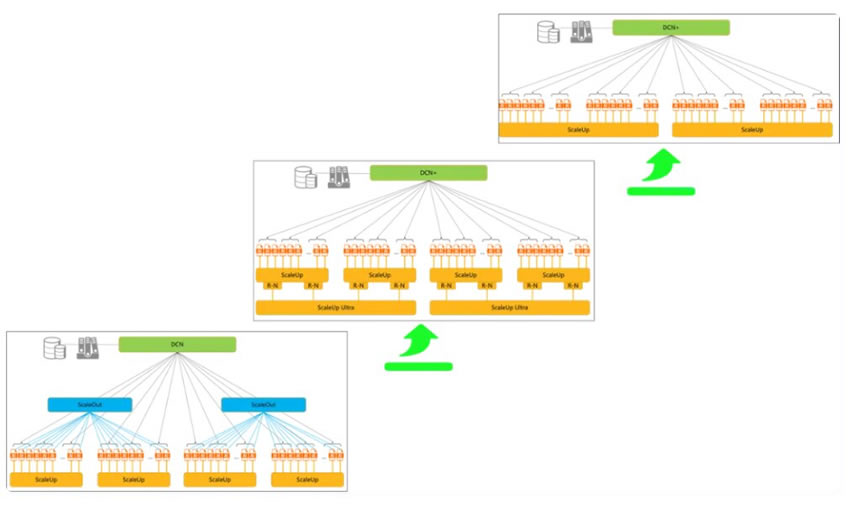
当然,超节点服务器的互连也会继续支持分层互连的更大规模的网络连接拓扑,提供更为灵活弹性的资源调度,同时也支持大规模集群的训练场景。磐久AI Infra2.0超节点服务器,目前仍支持三层的互连网络架构,第一层就是超节点内的ScaleUp互连,第二层是超节点间的ScaleOut网络,第三层是超节点与数据中心互联互通的DCN网络。
第一层:超节点内ScaleUp互连:单级交换,非以太ALink协议
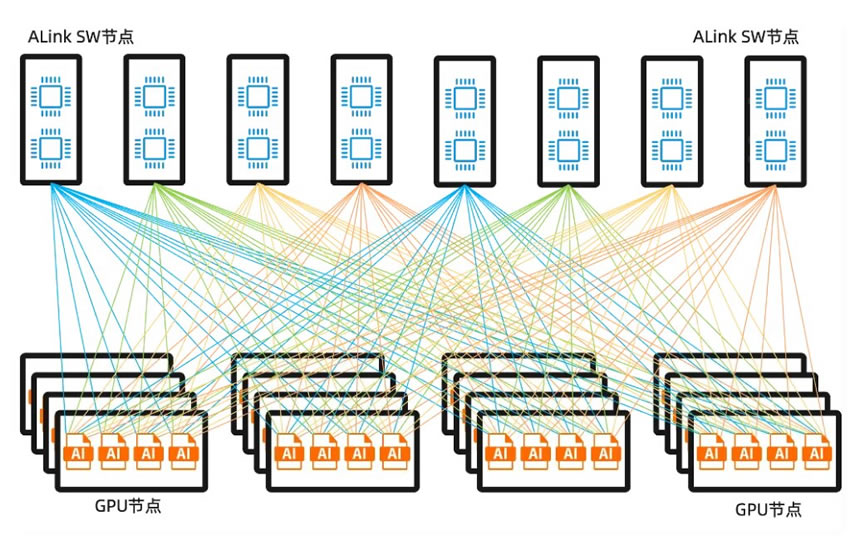
打开磐久AI超节点服务器,正视图左上区域是一组64~72卡超节点ScaleUp互连域,由正面的16~17个GPU节点,背面是8个ALink SW节点共同组成。每个GPU节点内置4颗GPU芯片,每个ALink SW节点内置多颗ALink Switch芯片,实现单级交换拓扑下的64~72颗GPU芯片ScaleUp域内全带宽全互连。
具体的超节点内ScaleUp互连拓扑,如下图,以使用64端口的ALink Switch为例,每个ALink SW节点内置1-2颗ALink Switch芯片,16个GPU节点上的64颗GPU芯片,每颗GPU芯片的ScaleUp port0/8通过正交连接器连接到ALink SW0节点上的ALink Switch芯片,每个GPU芯片的ScaleUp port1/9通过正交连接器连接到ALink SW1节点上的ALink Switch芯片,以此类推。对于上下两组AL64卡超节点互连域,是支持交叉扩展连接的,但是,在ScaleUp单级交换的原则下,需要使用支持128端口的ALink Switch芯片。
当前架构的超节点内ScaleUp互连,为每颗GPU芯片预留了最大128组高速互连serdes,最高可以达14T~28Tb的互连带宽/GPU。ScaleUp互连采用单级交换拓扑,是为了发挥ScaleUp互连的极致低延时特点,缩短E2E的推理任务完成时间,这也与ScaleUp互连协议采用GPU原生内存语义的ALink协议相互呼应,在极简的通信协议下,获得极致的数据通信延时,缩短单任务推理的E2E延时,提升用户的大模型推理体验。
Scale Up互连作为三个互连维度中带宽最高的维度,由于其对于面对的AI流量特点、性能的极致要求和实现挑战,存在极强的原生为现代GPU设计的需求,包括:
原生内存语义:可以实现GPU的计算核心直接访问,同时易于通过接口挂载到SoC总线,没有转换开销和对于计算核的侵入设计。 极致性能:能够达到极高的带宽(整芯片可达TB/s级),极低的时延。除了协议的高报文效率以外,也需要在高负载下的具备优秀的表现。 极简实现:最小化芯片占用成本,通过尽量小的芯片实现面积,将宝贵的资源和功耗留个GPU芯片的算力和片上存储。 高可靠链路:在Serdes密度非常高的环境下,通过高性能的物理层,并加以链路级重传和故障隔离机制,保障高可用性。
目前业内主流GPU的ScaleUp互连协议,都是以GPU计算为核心的第一性原理出发的同时,满足以上提到的多个维度需求,其中用到了包括Flit帧格式、LLC、CBFC等一系列技术。国际开放标准UALink、NVIDIA的NVLink、昇腾的UB、以及其他高效GPU互连协议xCN,都是采用类似的技术作为ScaleUp互连协议基础,并采用独立的数据链路层及以上格式,而非以太网协议。
一个戏谑的现象是,近两年行业出现的意欲用在ScaleUp的UEC、SUE、ETH+等协议,也都相继抛弃了以太网的帧格式,甚至修改了以太网的前导码,只为达到与GPU原生ALink协议相近的技术效果,虽然它们都还打着“以太网”的噱头,但是不能和标准的以太网协议,也没有IP地址的概念,本质上已经不是以太网协议。
行业的技术竞争,对于产业的发展终究都是好事,也会更快促进AI互连网络的快速革新,因此,此类对以太网协议大幅度裁剪和变形的做法,也对超节点服务器间ScaleOut的协议迭代提供了很好的借鉴意义,后文会展开介绍。
第二层:超节点间ScaleOut网络
为支持更大规模的GPU互联集群,应对大模型训练、计算资源灵活调度等诉求,磐久AI超节点服务器仍是支持跨超节点的ScaleOut网络。
打开GPU节点,可以看到节点的前窗有4张高性能网卡,可以为每颗GPU提供400~800Gbps的ScaleOut网络带宽,总体上磐久超节点服务器预留了25.6T~51.2Tbps的超节点间网络通信带宽。结合ScaleUp+ScaleOut通信优化技术,无论是超节点域内、还是超节点域间,都可以做到GPU-GPU 10Tb以上的通信带宽,为大模型推理、训练场景提供充足带宽。
前文提到,UEC、SUE、ETH+等协议抛弃以太网帧格式,对以太网协议进行大幅度裁剪和变形的做法,为我们提供了很好的借鉴意义。考虑到AI集群规模终究有限,万卡、十万卡的集群,叠加虚拟机划分,完全用不到48bit的MAC地址,或许24~32bit就足够用了。
因此未来ScaleOut也可以完全不必再基于以太网,可以采用更为简化的协议。GPU采用ScaleOut网络的数据通信,也是为了交换GPU之间的内存数据,通信的本质还是RDMA(Remote Direct Memory Access),因此当下ScaleOut采用的RoCE(RDMA over Converged Ethernet)协议,也应该面向GPU的内存交换本质,进行变革。在后文有关于ScaleOut网络流量的分解,我们再展开讨论。
第三层:数据中心互联DCN网络
无论是大模型推理还是训练,仍然离不开数据中心网络,用户的输入、互联网检索、训练数据、KVcache缓存、checkpoint备份等等,都依赖数据中心网络提供数据存储和交互。
因此磐久超节点服务器仍提供接入数据中心网络的接口,在CPU节点上,集成了一张400G~800Gbps的智能网卡,为GPU提供接入存储、数据库、数据预处理、数据计算加速等能力。
总体而言,超节点服务器的主要价值在AI大模型推理场景,在未来2-3年模型参数普遍达到10万亿量级时,超节点服务器的ScaleUp域在128个节点左右,是最佳的应用与工程实现的平衡点:
大模型推理场景是时延敏感型场景,在推理质量达到用户期待的同时,用户会更加关注延时体验。因此,超节点服务器的ScaleUp互连协议在满足带宽设计的同时,要更关注通信延时。在ScaleUp域互连拓扑设计上,采用单级交换互连,保持延时优势。二级交换则会增加延迟,意义不大;超节点的Scaleup的规模之需要满足未来大模型推理的应用,Scaleup规模不需要很大,128是当前最具性价比的选择。
传统的单卡、8卡AI服务器,还是以CPU为中心的体系架构设计,所有的GPU都是通过PCIe连接到CPU,再由CPU控制网卡完成GPU间、GPU对外的数据通信。
到了超节点服务器时代,我们看到了一些改变,开始围绕着GPU为中心来设计服务器:
为了扩展GPU的缓存容量和带宽,CPU与GPU的互连接口从传统PCIe替换成xLink C2C;
为了便于GPU访问RDMA网络,RDMA网卡直连到GPU.......
但是,这些技术演进还不够彻底,仍保留着以CPU为中心的设计理念,譬如RDMA网卡还是通过PCIe互连到GPU,GPU访问SSD仍绕不开CPU和PCIe,IBGDA技术仍然不是为GPU原生设计的,等等。
未来,AI超节点服务器,需要以GPU为中心,重构互连架构,下面有四个研究方向的构想。
方向一:以ScaleUp互连协议为基础,将CPU、存储、IO、加速器等互连到GPU上,打破PCIe的带宽限制
目前产业界已经卖出了第一步,通过C2C协议,扩大CPU与GPU之间的带宽,例如英伟达使用NVLINK C2C将CPU接入GPU。下一步则是要验证如何将Memory、网卡、加速器等外设连接到GPU。
方向二:重塑存储、IO、加速器的访问方式,支持内存操作语义,简化GPU操作,且支持高并发访问
第二个方向,则是重塑GPU与外设的访问方式。传统外设,如网卡,控制和操作比较复杂,CPU的微架构擅长做这样的驱动控制操作,但这对于GPU SIMT架构非常不友好,会严重浪费GPU的算力内核。针对GPU-GPU间内存交换的典型场景需求,设计一个ScaleUp Ultra卡,对本地GPU呈现远端GPU的内存地址和内存语义,实现跨域地址翻译和数据搬移。本地GPU只需要使用简单的内存语义向远端GPU内存地址发起数据读写,其他的复杂驱动控制、地址翻译、报文封装等,都交给ScaleUp Ultra卡卸载好了。
方向三:简化GPU互连网络拓扑,减少网络开销
传统GPU集群采用经典的三层互连架构:ScaleUp互连 + ScaleOut网络 + DCN网络,彼时GPU Scaleup域只有8~16卡,依赖ScaleOut网络构建万卡集群进行训练。
未来,如果大模型的参数规模超过百万亿参数级别,超节点服务器的GPU ScaleUp域需要扩大到256~512卡,大部分的通信流量都可以在ScaleUp域内完成,对于跨域ScaleOut的流量诉求在减弱。
同时,伴随着DCN网卡的带宽成倍增加(400Gb->1.6Tb),超节点服务器的跨域流量是否还需要ScaleOut网络?是否可以直接承载到DCN网络上?这是下一步互连架构需要探索的命题。当然,这会带来更多的技术问题,如传统DCN网络流量与ScaleOut网络流量的隔离等等。
为此,我们提出一种面向AI超节点服务器的两层互连架构设计思路:ScaleUp互连 + 高带宽DCN网络。分解ScaleOut网络的流量,一部分向下承载到ScaleUp互连域,一部分向上承载到高带宽的DCN网络。
简化网络分层,不仅可以简化公有云大规模GPU集群部署的复杂性,也可以降低专有云小规模GPU集群部署的底座成本。当ScaleUp互连域规模能够满足大多数TP+EP等高带宽/低延时的并行计算需求时,跨域的流量可以由高带宽的DCN网络承载;反之,则需要再增加ScaleUp跨域通信能力。
传统ScaleOut网络承载的通信数据,主要还是GPU与GPU之间的缓存数据交换(即RDMA通信),这与ScaleUp互连域内的GPU数据交换是类似的,这也使得在ScaleUp上承载部分ScaleOut流量成为可能。当然,传统ScaleOut网络实现更为复杂的网络拓扑和可靠性的增强能力,如多路径传输、乱序接受、拥塞控制、端到端可靠重传等,这些技术方案如果直接叠加到ScaleUp互连协议上,反而是增加了ScaleUp的复杂性。
可行的实现方案是,使用前文提到的ScaleUp Ultra卡实现跨ScaleUp域通信,类似跨域的GPU Agent。这样,也解决了当下GPU通过IBGDA进行数据传输时,GPU芯片对RDMA网卡的操作而浪费的无效算力。而跨ScaleUp域通信协议上,可以在ScaleUp协议上进行增强(ScaleUp Ultra),可以借鉴IB协议,也可以在ScaleUp协议上增加跨域路由字段,因为节点数规模终归有限(<100K级),因此也无需承载到48bit MAC地址的以太网协议。
方向四:ScaleUp互连走向光互连,进一步缩减通信延时
光互连技术,也是近2年的热点技术,LPO、NPO、CPO,尤其是CPO技术着实吸引眼球。那么超节点服务器的ScaleUp互连是否会选择光互连技术,以及何时选择、选择什么技术与模块形态,也是热议的话题。我们从超节点服务器互连技术演进和光互连技术两个视角出发,探讨一下这个话题。
首先,光互连的技术优点在于长距传输时信号速率高、损耗低、线径细(容易理线和运维)、波分复用技术还可以再进一步减少光纤数量;然而,光互连的缺点则是成本高、功耗大、可靠性降低。
目前单柜128卡在供电、散热、空间布局上,已经基本接近极致,如果模型规模继续增大,ScaleUp互连域的规模需要持续增加到256~512卡,那么ScaleUp跨柜互连就会成为必然;同时,AI芯片ScaleUp带宽还会持续增长,在serdes速率增长的进度相对偏慢的情况下,ScaleUp互连的serdes数量会加剧;为此,电缆连接器密度、电缆线径、电缆数量和理线运维复杂度(带来的潜在可靠性风险)都会持续增大。
因此,基于长期技术演进的需要,超节点服务器的ScaleUp互连,会选择光互连技术的时机大概是在ScaleUp互连域达到256卡、serdes速率达到448G、且光互连的端到端成本降低到与电缆的端到端成本相当时。
光互连的模块形态有多种,目前常见的有CPO、NPO、LPO等模块形态,不同模块的形态差异性,这里不展开介绍,从超节点服务器的硬件工程实现出发,会优选NPO的模块形态。
我们对比一下CPO/NPO/LPO的技术优缺点:
使用光互连技术后,在板级工程上还会带来更多的技术收益,包括:可以减少retimer芯片的使用,对冲一部分光互连的成本;获得更低的信号衰减,因此可以在ScaleUp协议的物理层采用效率更高的RS编码,换取更低的编码延时,进一步降低ScaleUp通信的时延。
但是,光互连技术在超节点服务器ScaleUp互连上还有更多挑战需要应对,首先就是可靠性,光的可靠性与温度有较大关系,可以使用液冷散热让NPO模块及其光源保持在较低的温度,从而获得更高的可靠性;另外,还需做好光连接器插拔接口的密封性设计,降低环境粉尘造成的可靠性风险;其次是可维护性,NPO、光源及光连接器接口,都要支持可插拔,便于故障时的快速维护,缩短MTTR。
另外,GPU与Switch之间的ScaleUp互连拓扑是一种交织的Mesh结构,这就会引入光纤的网状连接复杂性(类似电缆的CableCartridge的复杂性),造成一个光纤故障需要更换整个光纤组的陷阱,这也需要在工程设计时进行巧妙的规避。
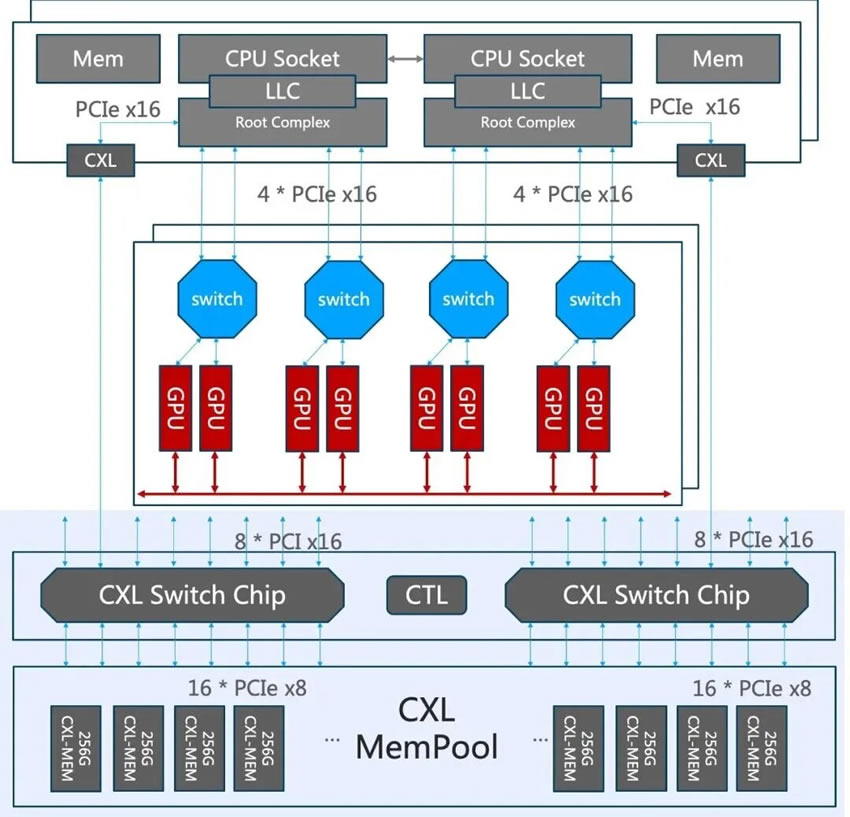
在非AI的通用计算场景下,CPU算力和内存的资源灵活配比是主要需求,但AI推理场景对于CPU计算节点提出了更高的需求,尤其是内存相关的特性。CPU在AI推理任务中承担的数据前处理和KV Cache存储,相对于普通的计算任务,需要更大的内存容量和内存带宽。从架构上来说,AI应用需要通算超节点要能够通过互连,实现大内存容量,高访问带宽。
// CXL协议很好的满足了CPU互连的原生需求
CPU的体系结构和计算任务相对于GPU,既有共性,也存在独特的需求,总体包括:
内存语义访问:支持CPU发起的load/store语义,以64Byte的CacheLine访问为典型报文长度,可以让CPU core无侵入改动下使用扩展内存
极致低延迟:相对CPU访问本地DDR内存在百ns的延迟左右, CXL内存也维持在百ns的延迟量级,以满足CPU上计算任务的要求,并最小化内存扩展下对于CPU芯片上缓存资源的要求
数据一致性:和CPU内部多核之间的MESI等一致性协议原生对接,不仅可以进行Prefetch等一系列硬件操作,更能让多个CPU之间能够在CL级别进行任务协同
在早期,行业主要依赖PCIe作为CPU与加速器或外设之间的标准互连协议,但PCIe本身不支持缓存一致性(cache coherency),导致CPU与设备间数据共享需要显式管理,增加了软件开销和延迟。
为解决这一问题,行业涌现了一系列用于CPU内存扩展的协议,包括IBM推出的OpenCAPI协议,ARM等公司提出的CCIX协议,多家公司联合推动的Gen Z协议等,在CXL(Compute Express Link)协议出现后,最终前面提到的协议或停止更新(如Gen-Z将技术转移贡献至CXL联盟),或不再针对内存扩展(如CCIX聚焦于ARM架构下CPU-CPU的专用连接)。
至此CXL协议作为CPU内存扩展的主流标准,以内存语义通信、允许不同组件之间的内存直接交互、最小化应用程序或处理器的参与等一系列特性,达到提升性能并降低功耗的目的。
// 计算-内存解耦的应用价值
解耦的架构下,节点的搭配更加模块化,除了性能之外,也带来更加弹性灵活等一系列优势,为AI推理和PolarDB数据库等典型场景带来价值,包括如下:
推理性能提升:通过挂载GPU的多个CPU节点共享一个CXL内存池,形成了KVCache无需通过主机内存转发,链路短;传输与计算的同步无需CPU同步,同步少;
多节点KVCache数据共享,功能易扩展:在KVCache命中场景下,访问延迟相较于基于RDMA构建的KVCache内存池(MoonCake),TTFT降低82.7%,吞吐提升4.79倍。
// 通算超节点服务器的互连架构及技术趋势
第一,基于CXL互连,实现计算与内存解耦,存储分层架构。
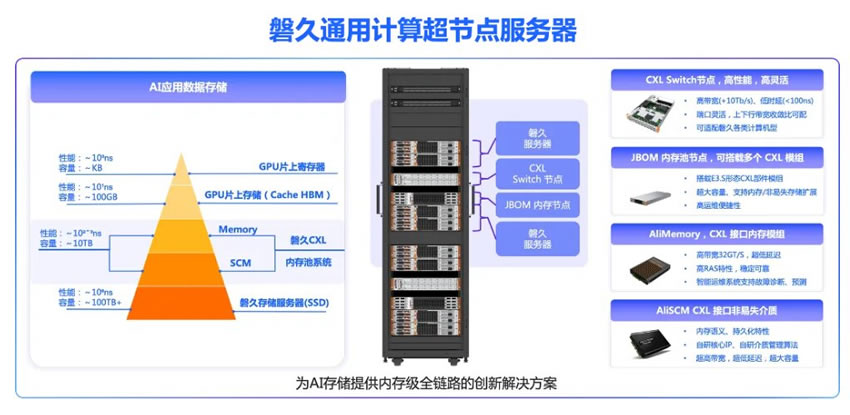
架构演进:通过磐久CXL超节点服务器,为CPU节点提供了百ns级延迟,百GB带宽,10TB级内存容量的弹性内存池,形成了整机柜的分层内存解决方案,通过逐级的内存架构,为应用在性能优化、成本竞争力提供。
通过CPU通用计算节点、Switch交换节点,JBOM内存节点,兼顾灵活性与高性能内存扩展。
图|为AI存储提供内存级全链路的创新解决方案
第二,超大带宽、串行化内存技术的设想与CPU体系架构的演进。
另一个技术趋势来源于CPU的内存IO演进领域。当前CPU芯片发展在IO领域存在挑战,其一是访存能力和CPU和算力能力配比,越来越难以满足AI为代表的各位应用的诉求,CPU的核心数和算力能够随着3D堆叠和封装保持较快的增长速度,但是传统的DDR总线的吞吐能力迭代愈发困难,其原因包括:
单Pin速率制约,由于当前DDR总线采用单端信号,到了DDR6可以达到12,800 MT/s以上,但这相对于Serdes速率(PCIe Gen6 64GT/s,Gen7 128GT/s)有数量级差异
芯片封装下的Pin脚占用过多
DDR并行总线下模式下对于PCB Layout要求较高,对于DQ总线的skew有要求,同时也对于服务器主板的布局布线存在难度
架构演进:CPU通过直插CXL内存,承担大容量主存,搭配少量甚至去除传统的DDR内存,形成适合AI应用的高带宽、大容量内存架构。以8*16 Lane的128对 CXL serdes(PCIe 6.0速率)IO为例,可以提供读写双向共2TB/s的内存带宽,如果完全去除 CPU DDR控制器和IO,可以达到更高的速率。
图片
AI大模型的到来,为服务器的设计实现带来了技术和工程挑战,更多的还是机遇。超节点服务器更是应运而生,无论是AI超节点服务器还是通算超节点服务器,都是为了提供更高密度的计算、缓存、IO资源,让局部并行计算更快、更高效。超节点服务器与传统服务器的最大变化就是互连,而超节点服务器与数据中心仓库服务器(Warehouse-Scale Computer)的差异性则是在互连规模、带宽和延时。
尤其是面向大模型推理场景,端到端延时是用户体验的关键要素,因此超节点互连的带宽和延时是核心命题,从低延时ALink协议/CXL协议、到单级互连拓扑、到有限节点规模,都是为了达成这一设计目标。磐久超节点服务器会拥抱开放标准,与产业界合作伙伴共建超节点服务器的未来。
2025云栖大会上,阿里云发布了全新一代磐久AI Infra2.0 AL 128超节点服务器。深度长文!详解阿里云磐久AL128超节点服务器及互连架构。
|
|